Potential solutions to practice exercises
Different people might approach these practice tasks in very different ways so these solutions are suggestions only. They are offered here to provide some guidance for people who might otherwise struggle with laying out steps.
Practice 1. Creating backup copies of files
In a folder, we have 250 image files for which we want to create backup copies before we process the images for archiving. Manually creating 250 copies of files seems like a very boring thing to do, so we are going to automate the workflow to create the backup copies.
This is a perfect task for a loop, as the task is simple and repetitive.
Potential solution
Steps in the copying process

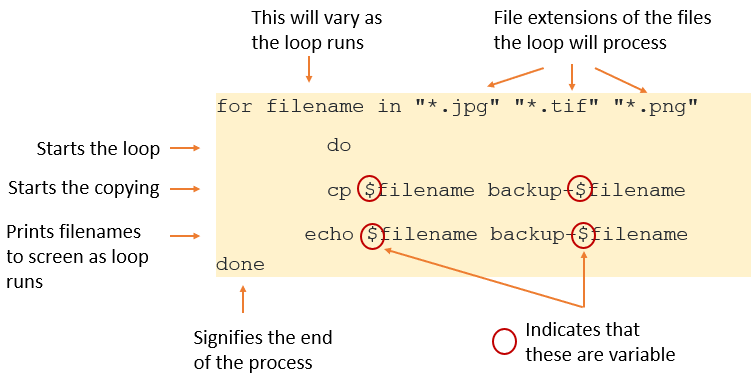
Example code in the Unix shell
for filename in "*.jpg" "*.tif" "*.png"
do
cp $filename backup-$filename
echo $filename backup-$filename
done
Notes
In the code example above, the loop will run through the folder creating back up copies of all the files with the file extension .jpg. As each file is copied, each original filename and the filename of each new file will be printed to the screen.
Then the loop will restart and repeat the process for all the files with the file extension .tif, again printing the original filenames and the filenames of the new files to the screen.
Then the loop will restart and run through the folder a third time, creating back up copies of all the files with the file extension .png, again printing the original filenames and the filenames of the new files to the screen.
The loop will then stop, as there are no more variables to work on.
Practice 2a. Tidying up
We have a large folder of files left over from a project that is now finished. The files are all sitting in the one folder which makes it hard to navigate. We want to archive the project and its files, but in the process, we want to create folders by file type, e.g., .pdf, .jpg, .doc, so that anyone wanting to access those particular file types can do so easily. We also want to delete files that have no file extensions. New folders will need to be created and the different files moved into them by file type.
Potential solution
Steps in the moving process
- Identify the different file types in the folder.
- Create new folders to house the different file types.
- Create a series of loops to work through the folder, file type by file type, moving the files to the correct folders.
- Once the final loop has run, delete all remaining files left within the main folder.
- Print filenames to the screen as the loop runs to verify it is working as required.
Using a shell script to automate the work
The task above could be fully automated using a shell script. A shell script is a text file containing a sequence of commands for a UNIX-based operating system that allows those commands to be run in one go, rather than by entering each command one at a time. Scripts make task automation possible. The script would contain the commands to do the tasks listed above, such as folder creation, file movement using loops, file deletion and so on. The benefit of shell scripts is that the code they contain can be re-used or adapted for similar tasks.
Practice 2b. Tidying up more carefully
In the process of doing the above, we actually made a few blunders. We accidentally deleted some files we should have kept either because they were missing a file extension. Because this automation is a complex operation that cannot be undone, we want to make sure we don’t make those kinds of mistakes again.
One way to do that is to check we have coded the workflow correctly before we finally execute the automation, possibly by simply printing to screen all the relevant filenames prior to moving them - that way, it is possible to check we are working on the right files before any action is taken.
To prevent accidental deletion of files, we could introduce a step to check whether or not to delete a file, e.g., by using the remove command rm in the Unix shell with an -i flag. The -i flag forces the system to ask for confirmation on whether or not to delete a file. One can answer either Y or N to the example below.

Practice 3. Managing incoming data
Suppose you have a number of acoustic listening devices set up in the bush. Every day, you receive an email from each device with an attached data file recording that day’s activity. In order to analyse the data from the devices, all the separate daily data files need to be combined weekly into a single file. It is important that each device ID is listed within a column in the combined data file to identify all the different locations.
In order to analyse the data over time, you need to append the weekly file digest to the existing, now very large, main data file. Before adding anything new, and in order to safeguard the integrity of the data, you need to create a backup of that main data file and send a copy of that backup file to your cloud storage account for safekeeping. Once the new data has been appended, you need to rename the new main data file with today’s date as part of the file name, and run software against the file to ensure the integrity of the data, e.g., to check that no data is missing (which might indicate a malfunctioning device).
Steps in the data combination process
- Create a new copy of the main data file with today’s date as part of the file name.
- Move the previous version of the main data file to cloud storage.
- Save all the new data files individually to local storage with the device ID of each as part of the file names.
- Create a new weekly data file digest into which the daily digests from the different devices will be imported.
- Import each daily digest to that data file with an
appendcommand, ensuring that the device ID relating to each file’s data is written into a separate column. - Append the weekly digest to the newly renamed main data file.
- Verify that no data is missing. In OpenRefine, using
Facet by Blankon the relevant data fields could be one way to verify that no data is missing.
Using a shell script to automate the work
Again, a shell script could be used to automate this work. Given that these tasks are run weekly, it would make sense to turn this into an automated task rather than a manual one as that will not only be faster, but will reduce the opportunity for error.